
seleniumを使用したインスタグラムの自動いいねツールのソースコードを公開します。
当ツールは、2021/6/8(火)時点では動作を確認しておりますが、Instagram.comの仕様変更で正常に動かない場合もあります。
インスタグラム自動いいねツールの概要
コードはPython3で記述されています。
Pythonを実行できる環境があればコピペで使えると思います。
また、Git Hubにメインの実行ファイル以外に必要なファイル群もまとめてありますのでそちらも参考にしてください↓

- インターネット
- selenium
- chrome driver
- Python3
インスタグラム自動いいねツールの問題点
ここ最近、インスタグラムが自動化ツール(Bot)への対応が厳しくなったように感じております。
もしくは、自動化ツール(Bot)をヘビーユーズしていた私のアカウントが対象となっているだけかもしれません。
いずれにせよ、画像の投稿もほとんどないような状態で自動いいねを繰り返していると、ブロックされてしまいます。
翌日など時間を開けておこなえば、また問題なく自動いいねをすることができますが、やはり一定数繰り返してブロックされます。
私はもう50回以上ブロックされています。
それでも、アカウントがBANされることはありませんでしたが、当ツールのテストのためにブロックされている状態で自動いいねツールをひたすら実行していたら、「あなたのアカウントが不正利用されているかもしれない」というようなメッセージが表示され、パスワードの変更を要求されました。
とりあえず、その対策としましてブロックされたら、処理を停止する機能はつけております。
しかし、大切なあなたのアカウントがもしBANされてしまっても責任は取れませんので自己責任でお使いになってください。
もしくは、selenium初学者の方がseleniumとはどんなもんぞや?と、さくっと実験する目的には向いているかもしれません。
※必読!おすすめ本
Instagramでビジネスを変える最強の思考法
インスタグラム自動いいねツールの機能
- ハッシュタグを指定して自動でいいね!
- ブロック時、処理終了機能
- 再いいね防止機能(1回いいねした投稿へいいねするとキャンセルになってしまうから。)
- 1日あたりのいいね回数制限機能
機能追加版
上記の機能へ〇〇回以上”いいね”されていた画像には”自動いいね実行”をスルーできる機能を追加したソースコードをnoteにて販売中です。
いいね!されている数が少ない投稿、アカウント(フォロワーが少ない可能性も高い)へ自動いいね!の対象を絞り、
無駄いいね!を減らし、効率よくフォロワーを増やすことが狙いです。
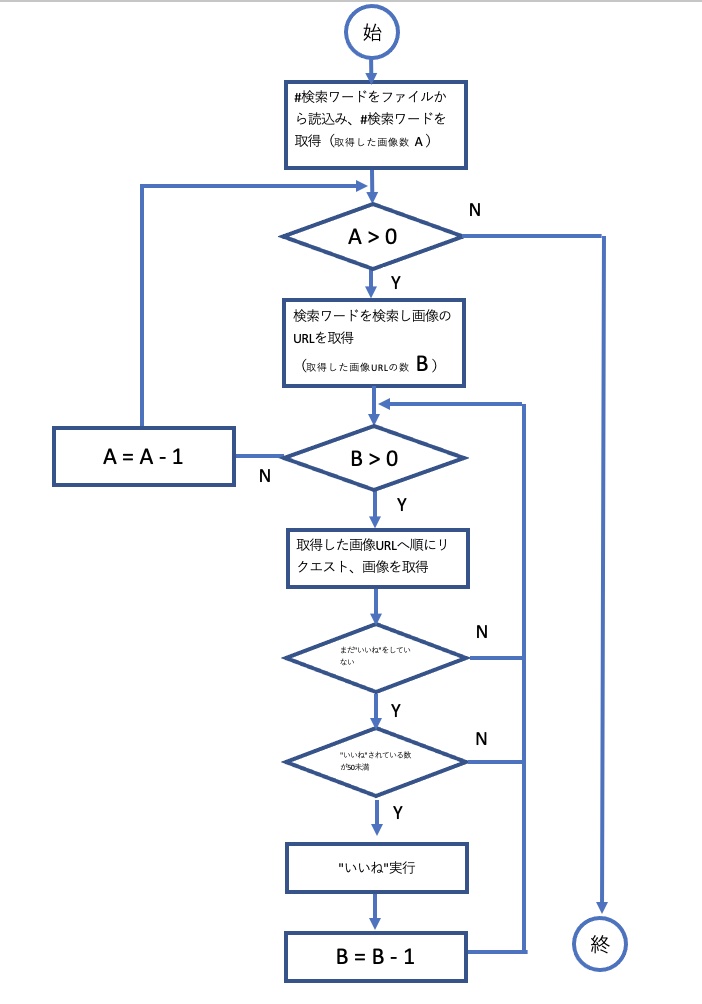
機能追加版のフローチャート

インスタグラム自動いいねツールのソースコード
インスタグラム自動いいねツールを動かすには最低限以下の4つのファイルを同一のディレクトリに配置する必要があります。
- app.py(実行ファイル)
- readfile.py(ファイル読み込み用の関数を記述したファイル)
- already_likes_url.txt(いいねした投稿のURLを収める)
- words_*.txt(いいねしたいワード(ハッシュタグ)を改行区切りで記述する。*に任意の数字を設定し、コマンド実行時の引数でファイルを選択する)
ディレクトリ構成はこんな感じです↓
└── instagram_hashtag2auto_likes_tool
├── already_likes_url.txt
├── app.py
├── readfile.py
└── words_1.txt
ツールを実行すると、いいねした数を日付で管理する”likes_cnt.txt”というファイルが自動で出力されます。”already_likes_url.txt”もそのようにすれば良かったのですが、後日暇ができたら修正するかもです。
app.py(実行ファイル)
24,25行目の”XXXXXXXXXXXXXXX”へ、いいねするインスタアカウントのユーザ名とユーザIDを記述してください。
1日に500回以上いいねする場合は、18行目の変数max_limit_likes_counterの値を修正してください。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 必要なライブラリのインポート
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import urllib.parse
import time
import datetime
import sys
import traceback
import readfile
args = sys.argv#コマンドの引数
####################設定####################
#1日にいいね!できる最大値。この数を超えたら処理終了
max_limit_likes_counter = 500
#自動いいね!時、エラーがこの数を超えたら処理終了
max_limit_error_cnt = 10
#Instagramログイン用 ID PASS
username = "XXXXXXXXXXXXXXXXXXXX"
password = "XXXXXXXXXXXXXXXXXXXX"
#読み込みファイル名
file_words = "words_" + str(args[1]) +".txt"
file_l_cnt = "likes_cnt.txt"
file_alu = "already_likes_url.txt"
#################いいね!したいワードをファイルから取得
words = readfile.readWords( file_words )
#############本日、いいね!している数をファイルから取得
today = datetime.date.today()
today = str(today)
likes_cnt,data_other_than_today = readfile.getLikesCntToday(today,file_l_cnt)
######################すでにいいね!したURLの読み込み
already_likes_url = readfile.readAlreadyLikesURL(file_alu)
#Chromeを起動
driver = webdriver.Chrome()
#Instagram ログインURL
login_url = "https://www.instagram.com/"
#ログインボタン
#login_path = '//*[@id="react-root"]/section/main/article/div[2]/div[2]/p/a'
#ログイン用フォームへのパス
username_path = '//form//div[1]//input'
password_path = '//form//div[2]//input'
#いいね!ボタン取得用
like_x_path = '//main//section//button'
#Instagramのサイトを開く
driver.get(login_url)
time.sleep(3)
#ログインページへ ( Webページの構造が変化しており、↓の処理はいらなくなった。2020.04.04 確認 )
#driver.find_element_by_xpath(login_path).click()
#time.sleep(3)
#ユーザー名とパスワードを入力してリターンキーを押す
usernameField = driver.find_element_by_xpath(username_path)
usernameField.send_keys(username)
time.sleep(1)
passwordField = driver.find_element_by_xpath(password_path)
passwordField.send_keys(password)
passwordField.send_keys(Keys.RETURN)
time.sleep(3)
if "アカウントが不正使用されました" in driver.page_source:
print(driver.page_source)
print("ブロックされました。パスワードを変更する必要があります。")
print("処理を終了します。")
exit()
#####################ハッシュタグ毎のループ
#ハッシュタグ検索用のURL
tag_search_url = "https://www.instagram.com/explore/tags/{}/?hl=ja"
off = False#処理を終了する切り替えスイッチ
error_cnt = 0
for word in words:
if off:
break
print("http req get hashtag page: " + tag_search_url.format(word))
driver.get(tag_search_url.format(word))
time.sleep(3)
driver.implicitly_wait(10)
#リンクのhref属性の値を取得
mediaList = driver.find_elements_by_tag_name("a")
hrefList = []
#1つのハッシュタグに表示された画像のhrefを配列に格納
for media in mediaList:
href = media.get_attribute("href")
if "/p/" in href:
hrefList.append(href)
#画像のhrefを格納した配列でループ処理
for href in hrefList:
#すでにいいね!していた場合はスルー
if href in already_likes_url:
print("[いいね!済]" + href)
else:
driver.get(href)
time.sleep(2)
try:
driver.find_element_by_xpath(like_x_path).click()
time.sleep(2)
#print(driver.page_source)
if "ブロックされています" in driver.page_source:
print("ブロックされました。処理を終了します。")
off = True
break
likes_cnt += 1
print('いいね! {}'.format(likes_cnt))
flc = open(file_l_cnt,'w')
flc.write(data_other_than_today + today + '\t' + str(likes_cnt) + '\n')
flc.close()
fa = open(file_alu,'a')
fa.write(href + '\n')
fa.close()
#[ already_likes_url ] へいいねしたURLを追加
already_likes_url.append( href )
#この地点を通過する時にいいね!max_limit_likes_counter(デフォルト値500)回超えてたら終了
#BAN防止
if likes_cnt >= max_limit_likes_counter:
print("いいね!の上限回数({})を超えました。処理を終了します。".format(max_limit_likes_counter))
off = True
except Exception as e:
ex, ms, tb = sys.exc_info()
print(ex)
print(ms)
traceback.print_tb(tb)
error_cnt += 1
time.sleep(5)
if error_cnt > max_limit_error_cnt:
print("エラーが{}回を超えました。処理を終了します。".format(max_limit_error_cnt))
off = True
if off:
break
print("本日のいいね!回数 {}".format(likes_cnt))
#ブラウザを閉じる
#driver.quit()
readfile.py(ファイル読み込み用の関数を記述したファイル)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import urllib.parse
#いいね!するワード(ハッシュタグ)を格納する配列を作成する関数
#numにはコマンド実行時の引数1が入る
def readWords(file_words):
file_check = os.path.isfile(file_words)
if file_check:#ファイルが存在した
print("######################################################################")
print(file_words + "を読み込みました。以下ワードのハッシュタグ付き投稿をいいねします。")
words = []
with open(file_words,'r') as f:
for row in f:
if row != "":
word = row.strip()
print(word + ",",end="")
#URLにそのまま日本語は入れられないので、エンコードする
words.append(urllib.parse.quote(word))
print("\n######################################################################")
else:#ファイルが存在しなかった
print( file_words + "が見つかりません。処理を終了します。" )
exit()
return words
#本日のいいね!した回数を取得する関数
def getLikesCntToday(today,file_l_cnt):
likes_cnt = ""
data_other_than_today = ""
file_check = os.path.isfile(file_l_cnt)
if file_check:#ファイルが存在した
with open(file_l_cnt,'r') as f:
for row in f:
if row != "":
date,num = row.split('\t')
#print(date)
#print(likes_cnt)
if date == today:
likes_cnt = int(num.strip())
else:
data_other_than_today += row
f.close()
#ファイル内に本日の日付が見つからなかった場合
if likes_cnt == "":
f = open(file_l_cnt,'a')
f.write(today + '\t0\n')
likes_cnt = 0
f.close()
else:#ファイルが存在しなかった
f = open(file_l_cnt,'w')
f.write(today + '\t0\n')
likes_cnt = 0
f.close()
print("本日({0})すでにいいね!している数 : {1}".format(today,likes_cnt))
return likes_cnt,data_other_than_today
#すでにいいね!したURLの読み込み、2回目のいいね!はいいね!キャンセルとなってしまうため、防止機能用
def readAlreadyLikesURL(file_alu):
already_likes_url = []
f = open(file_alu,'r')
for row in f:
if row.strip() == "":
continue
already_likes_url.append(row.strip())
f.close()
return already_likes_url
インスタグラム自動いいねツール実行方法
コマンドはUnix系の端末用です。Windowsを使用の場合は調べてください。
1.ファイル準備
こちらの説明では、わかりやすいようにGitHubからディレクトリごとダウンロードしデスクトップに配置します。
https://github.com/jj-matsumoto/instagram_hashtag2auto_likes_tool
2.端末を開き以下コマンドを実行
cd ~/Desktop/instagram_hashtag2auto_likes_tool-master
↑先程の説明では、ディレクトリ名は「instagram_hashtag2auto_likes_tool」でしたが、GitHubからダウンロードしたままの設定で「-master」がついています。
vi app.py
↑24,25行目の”XXXXXXXXXXXXXXX”へ、いいねするインスタアカウントのユーザ名とユーザIDを記述。
3.いいねするワード(ハッシュタグ)をwords_*.txtへ記述
vi app.py
GitHubからダウンロードしたファイルには鎌倉‥となっているので好きなワードへ変更する。
4.コマンド実行
python3 app.py 1
GitHubからダウンロードしたファイルは「words_1.txt」となっているので引数に1(半角)を設定しコマンド実行
インスタグラム自動いいねツール エラー事例
HTMLオブジェクトが取得できていない
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {method:xpath,selector://form//div[2]//input}
(Session info: chrome=XX.X.XXX.XXX)
上記のようなエラーメッセージが出力された場合は以下2点のような原因が考えられます。
①インスタのWEBサイトの仕様変更がありHTMLの構造が変化した。
取得するべきHTMLオブジェクトへのパスが変化してしまって指定のパスにHTMLオブジェクトが無い場合、上記のようなエラーで処理が中断されます。
driver.find_element_by_xpath()へ設定する値を、クロームのデベロッパーツールを使用して探してください。
「xpath クロームデベロッパーツール」などでググると調べ方を丁寧に説明してくれているサイトが見つかります。
②通信速度などの影響によりブラウザがHTMLを読み込み終わる前に”driver.find_element_by_xpath()”でHTMLオブジェクトを取得しようとしている。
ソースコード中にある”time.sleep(n)”はn秒待機という命令です。
これは、ブラウザがHTMLを読み込み完了する時間を考慮して設定しています。
なので、ソースコードのところどころに”time.sleep(n)”の記述があります。
このページに掲載しているソースコードの”time.sleep(n)”は、以前に自宅で自動いいねしまくっていた時に調整した数値です。
余裕を持たせた設定にすれば確実なのですが、あまり余裕を持たせると、時間あたりのいいね数が少なくなってしまったり、起動に時間がかかりすぎてしまうという問題があります。
なので、”time.sleep(n)”は通信環境や読み込むページのデータ量などによりご自身で調節してみてください。
不具合やご質問があれば、コンタクトフォームからお気軽にご質問ください。
ご連絡はTwitterのメッセージからもどうぞ→@ang_tools


コメント